2020年9月のkintone連携サービス バージョンアップ情報

こんにちは。やなせです^^
肌寒くなってきて「秋」という季節がほんの少し感じられるようになってきましたね。
さて、今回より毎月1回、その前の月に行ったkintone連携サービスの
バージョンアップ情報をブログ記事でご紹介していきたいと思います!
今年の4月からバージョンアップ情報を毎月YouTubeでご紹介してきました。
過去の動画をご覧になりたい方はこちらよりご覧ください。
目次
【フォームブリッジ】kintoneアプリにフィールドを同期して保存」機能の追加
これはバージョンアップ時に大きな反響があった機能になります!
基本的にフォームブリッジでフォームを作成するときは、kintoneアプリを作成してからフォームを作成します。
そして、後からフィールドを追加したいときは、kintoneアプリにフィールドを追加してからフォームブリッジの
「kintoneアプリからフィールドを同期」でフォームブリッジにフィールドを同期させるという手順でした。
9月のバージョンアップでフォームブリッジのみの操作でkintoneにフィールドを作成して同期することができるようになりました!
詳細をご案内しているブログがすでにありますので、是非こちらをご覧ください。
【プリントクリエイター】アプリ連携のインターフェイスの改善
アプリ連携のインターフェイスを改善しました!

画像のようにアプリ連携の一覧画面をアプリ一覧、帳票一覧画面に準じたものに変更しました。
またアプリ名で検索、ソートができるようになりました!
【kMailer】Office365 の OAuth 連携に対応
連携されているメールサーバーの割合として、GmailとOffice365で約7割を占めています。Gmailは以前よりOAuth連携に対応しておりましたが、9月のバージョンアップにてOffice365もOAuth連携できるように対応致しました!
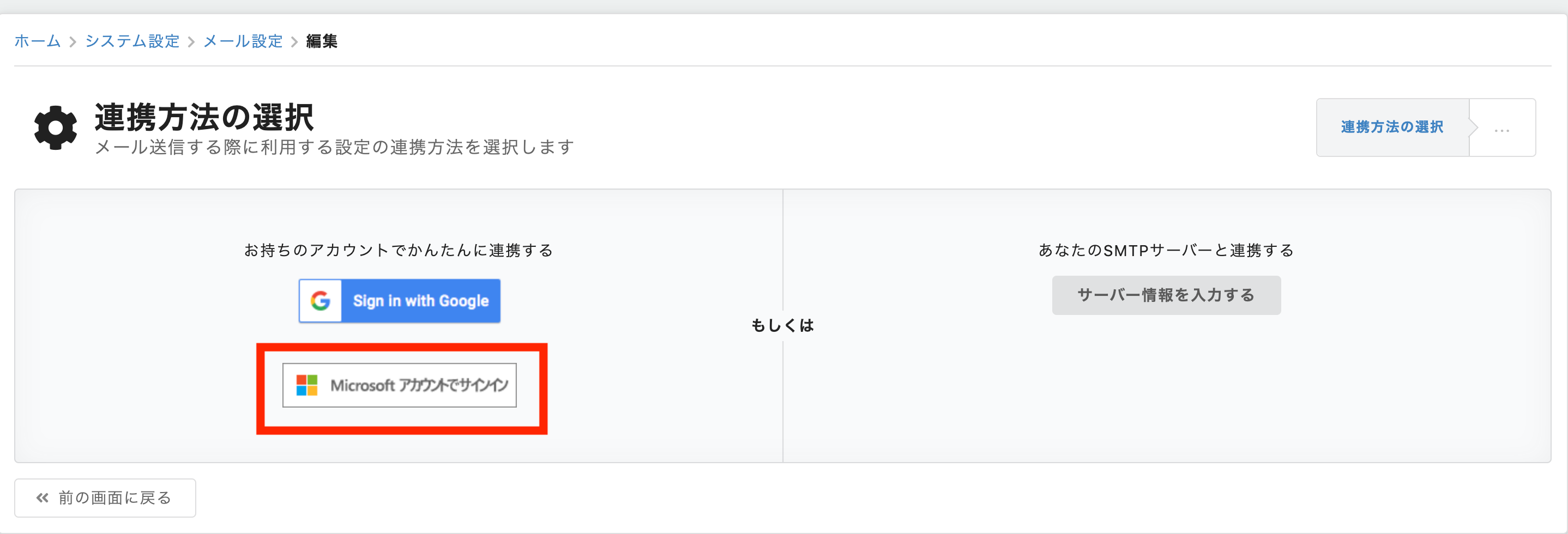
「システム設定」>「連携方法の選択」よりOffice365が選択できる!
【kMailer】パスワードの表示/非表示切り替え機能の追加
ログイン画面でログインメールアドレスとパスワードを入力してkMailerにログインしていただきますが、
今までパスワード入力中、パスワードは非表示となっていましたが、表示/非表示を切り替えることができるようになりました!

ログイン画面でのパスワード非表示

ログイン画面でのパスワード表示
これにより、パスワード入力ミスを防げますね!是非ご確認くださいませ。
【データコレクト】STDEV関数とSTDEVP関数のサポートを追加(標準偏差)
まず標準偏差と分散とについて少し解説します。
偏差…平均に対してのそれぞれの値のデータの差。
以下5人の身長の平均は169cmになります。
ですので、
170cmの人は平均169cmに対し、+1cmの差があるので偏差+1
165cmの人は平均169cmに対し、−4cmの差があるので偏差−4
となります。

このAグループの身長の平均値が他のグループの身長と平均値とどのくらいばらつきがあるのかを知りたい。。。

標準偏差…あるグループの偏差を平均化したもの。ムラやデータのばらつき具合を数値化したもの。
この標準偏差を求めることによって、Aグループの身長の平均値とBグループグループの身長の平均値のばらつき具合を算出して比べやすくなります。
 標準偏差は偏差を平均化するので算出方法として、それぞれの偏差の和÷データ数で出せると思いがちですが、
標準偏差は偏差を平均化するので算出方法として、それぞれの偏差の和÷データ数で出せると思いがちですが、
上図のように+と−の値があるため、打ち消しあってしまうのでそれぞれの偏差の値を2乗します。
ただし、データ数(=ここでいうAグループの人数)が増えるほど値が大きくなります。
その為、異なったデータ数の結果同士を比較できません。
例)100人グループの身長の偏差平方和とAグループの身長の偏差平方和 にはかなりの差が出ます。その為、データ数5で割ります。

それぞれの偏差の値を2乗してデータ数で割ると分散が算出できます。
ただcmとcm2は単位が異なりますので、平方根をとります。
そうすることで標準偏差(=偏差の平均値)を算出することができます。
・STDEVP関数とSTDEV関数の違い
STDEVP関数…標本そのものを計算した標準偏差
STDEV関数…データを母集団とみなしたときの標準偏差(=5人をもっと大きな母集団とみなしたときの標準偏差)

168cm・170cm・171cm・167cm・171cm のBグループも同じ169cmが平均となりますが、
この標準偏差は1.62になります。
AグループとBグループの標準偏差を比較すると、AグループよりBグループの方が標準偏差が小さいということがわかります。
では、データコレクトでのフィールド式設定方法です!
 データの値が保存されているアプリを入力元データで指定し、
データの値が保存されているアプリを入力元データで指定し、
=STDEVP(アプリA!身長)
=STDEV(アプリA!身長)
とフィールド式を設定することで標準偏差を算出することができます。
【データコレクト】TTEST関数のサポートを追加(t検定)
まず「t検定」とは何か?という疑問を抱く方もいらっしゃるかと思いますので、簡単に説明させていただきます。
t検定は2つのデータが平均値の等しい母集団から取り出されたものかどうかを確率的に調べる検定になります。
t検定を行うための手順です。

これだけだとわからないと思うので、用語も説明します。
帰無仮説…最終的に捨てたい仮説なので[帰無]仮説と呼びます。「2つのデータに差はない、概ね等しい」
対立仮説…帰無仮説に対立する仮説。最終的に示したい仮説。「データには差がある」(前より後の方が大きい、小さいなど)
有意水準…「どのくらい低い確率なら帰無仮説を棄却できるか?」を示す基準となる確率の値。
P値が有意水準よりも小さい場合は帰無仮説は棄却され、「2つのデータに差はない」とは言えない、「有意差がある」と意味付けられる。
一般的に5%(0.05) 5%には根拠はない。1%とするときも 自分で決める値
P値…帰無仮説が正しいと仮定したときに、持っているデータと同じか、より顕著な差がでる確率=乱暴に言うと「偶然の産物で結果に違いがでた確率」これが小さいと、偶然の産物とは言えないだろう、と意味付けられる。計算で出す値
TTEST関数で返ってくる返り値はこのp値
ここでダイエット薬の投与前と投与後の体重データを比較してt検定を実施してみます。

ダイエット薬投与前の体重データ

ダイエット薬投与後の体重データ
TTESTの式はこちらの通りです。

TTESTの計算式です。
この尾部と検定の種類について説明します。
尾部…データ間のどのような差を見たいのかに応じて1もしくは2を指定します。
1を指定:データ1の値よりデータ2の値の方がが大きいか?(小さいか?)片側検定
例)テレビCM広告をうった。
その前後で問い合わせ件数は増えたか?
2を指定:データ1とデータ2に違いはあるか?両側検定
例)お菓子工場2つで同じ商品をつくっている。
工場間でお菓子のサイズに差はあるか?
検定の種類…データの性質に応じて検定の種類(1,2,3)を変える必要があります。
1を指定:比較するデータ間に対応関係がある場合
例)運動を行う前の人の健康データと運動後の健康データ。同一人物内で比較しないと意味がないので、データ間に対応があるといえる。
2を指定:比較するデータ間に対応関係がない場合(データの分散が同じケース)
例)広告を出す前後の新規問い合わせ件数データ。広告前に問い合わせた企業と広告後に問い合わせた企業との間にこれといった結びつきがない。
3を指定:比較するデータ間に対応関係がない場合(データの分散が同じとは限らないケース)
例)2を指定した場合の例について、広告前と広告後で問い合わせ件数のばらつき具合が異なるようなケース。
確証がない場合は3を指定してしまってよい。
1: 対をなすデータのt検定、2: 等分散の2標本を対象とするt検定、3: 非等分散の2標本を対象とするt検定
先ほどのダイエット薬投薬前と投薬後のデータをもとにt検定を実施します。

検定の種類はダイエット薬を投与する前と後でそれぞれ同一人物を指定しているのでデータ間に対応があるといえます。
よって「1」を指定します。
=IF(TTEST(ダイエット薬投与前体重データ!体重,ダイエット薬投与後体重データ!体重,1,1) <0.05,”棄却”,”採択”)
そして今回はダイエット薬投与前と投与後で「両者に差はない」という仮説(帰無仮説)を立てて、
TTESTで0.05(有意水準)より小さければ棄却される、大きければ採択されるという式を設定しました。
これを計算すると、0.05より小さい0.01という値が出てきたので棄却されます。
よって最初に立てたダイエット薬投与前と投与後で「両者に差はない」という仮説(帰無仮説)は棄却される、ということになります。
【データコレクト】「来年/来月/来週/明日/昨年/昨日」の絞り込みに対応
kintoneで8月に行ったバージョンアップで、
レコード一覧やグラフの設定で、レコードを日付で絞り込む条件に、
「来年/来月/来週/明日/昨年/昨日」を新たに指定できるようになったのですが、
データコレクトでも「来年/来月/来週/明日/昨年/昨日」の絞り込みに対応しました!
以上が9月のバージョンアップ情報になります。
10月のバージョンアップ情報について
【プリントクリエイター】各帳票設定の更新時の「Javascriptの送信」ボタンを表示するタイミングを改善し、
適切なタイミングで表示されるよう変更予定です。
こちらはすでにリリースしておりますが、来月のバージョンアップブログで詳細にご案内します!
以上です。
kintone連携サービスは30日間、無料でトライアル可能です!
気になる製品がありましたら、是非お気軽に30日間の無料お試しで試してみてください!!
ではまた来月のバージョンアップ情報もお楽しみに♪